Is it wrong? Is it right? I don't know..
...but it sure is funny. Anyone want a wooden Commodore 64 keyboard?
...but it sure is funny. Anyone want a wooden Commodore 64 keyboard?
When looking into why I was getting immediate notifications of a SQLDependancy being changed, I discovered a really nice MSDN2 page that documents the things to watch out for, Special Considerations When Using Query Notifications
Major things to note:
dbo.Address, but you should be doing that anyway or you don't get pre-parsed queries. This means that you are obviously? only allowed to talk to one database.AVG, MIN, MAX, DISTINCT, COUNT(*). You can use SUM on non-nullable columns in the presence of a GROUP BY, but no ROLLUP or CUBE.For full details, consult the article.
Regular readers of my blog (all 14 of you), will know that I'm a stickler for handling exceptions correctly in applications. I strongly believe that you should only catch exceptions you can handle, never catch something you can't correct for, unless you have signficant contextual information you can add, then use the InnerException property, yada, yada...zzzzzzz...
Sorry about that, you were dozing off.
Anyway, as I was typing... always log exceptions in detail using a top level handler, and only stay running if it makes sense; like in ASP.Net applications.
Most of that is easy, but what about when you have a background thread in an ASP.Net application? In CLR 1.1, an unhandled exception in a background thread just killed the thread, which is bad because you don't know that it is safe for other threads to continue, and a deadlock or static-data corruption is a very real possibility. Of course, you always wrapped your outer-most function for that background thread in a try {} catch (Exception ex) { /* log it */ throw; } block, so you at least logged it. In CLR 2.0, your (proper and correct) re-throw of the Exception will result in the Application being terminated. Bummer, but we'll come back to that.
Joshua Flanagan has put together a nice WaitCallback derived class that does all the by-rote work of wrapping a thread-top-level try {} catch (Exception ex) { /* log it */ throw; } block. If that was all it did, I wouldn't be wasting your time, nice as it is to StayDRY™.
Remember what I said about CLR 2.0 dumping your Application if the background thread had an unhandled exception? Remember the pattern of rethrowing at the top-level-catch? What if we could somehow marshal that thread's exception details over to the foreground thread(s) of the ASP.Net Application where it could be handled by the handy-dandy infrastructure setup in Global.asax's HttpApplication.Error or Application_Error.
That's where Joshua's cleverness shows. He has done just that, building a nice generic framework for turning the thread-top-level exception into an inline request to an HttpHandler, passing the serialized Exception details along. Once in the handler, it's simply deserialized and thrown anew, whereupon it is caught and logged as a foreground-thread exception.
Head over to Safely running background threads in ASP.NET 2.0 and get the goods!
With server-based IIS 7.0 you get easy compression of outgoing content, but for earlier versions compression is unavailable (workstation IIS doesn't even support it). For IIS versions above 5.0 you can get very good compression support from Ripcord Software. They've just released IISxpress 2.0, and it's really slick. The configuration is well integrated into the IIS pipeline and works in an opt-out paradigm so you can easily configure specific things not to compress (sub-sites, directories, file extensions, content-type, URI, client IP, etc.) You also can watch live statistics of the files and compression ratios as they are served.
The best part? It's free for non-commercial use and only $50 for commercial use (per server). That's almost as good a deal as Paul Wilson's Wilson O/R Mapper.
Download (or buy) IISxpress here.No remuneration was or will be paid for this recommendation, I just like this stuff
My vote was cast with the majority. "Net neutrality", as defined by the FCC, requires consumers' free access to any legal content, applications and devices of their choice. It also reduces the threat of gatekeepers over new content and services. In order to safeguard net neutrality, the bill contains language giving the FCC authority to intervene on a case-by-case basis, if such violations are alleged. These components and more eliminate the need for restrictive or premature "net neutrality" provision.
I personally disagree with your assessment of the protection provided by the base COPE Act. While I understand that you may disagree with the current language of the "Net neutrality" amendment, passage of the COPE Act without SPECIFIC language PREVENTING scaled-fee/rate-based-charge by the telecommunications provider levied on content providers will effectively allow discrimination of the right-to-publish based on economic means of the provider. In addition, such scaled-fee/rate-based-charges allow a second charge above and beyond what said providers are already paying for the bandwidth they use.
The language does protect the cosumer's right to recieve information, but does NOT sufficiently protect the right of publishers of that information. What good does it do for me to freely access information at a (intolerably) slower rate, merely because the publisher doesn't have deep enough pockets to pay MORE for services they've already paid for in terms of the datarate agreements and connection sizes thier provider is already contractually obligated to provide? Moreover, can you not see the danger of each level of provider layering more and more charges to those under, ending when the two or three providers at the top of the Internet peering hierarchy collecting money from everyone and benefitting no one.
The stated reason for a scaled-fee/rate-based-charge is to "make the publisher responsible for the largest bandwidth use pay for the privilege of higher-rate delivery". This is completely against what the Internet was, and continues to be, about... free access to information and the right to publish content that the CONSUMER pays to access, and the PUBLISHER pays to provide, through line connection fees and bandwidth-related charges. A delivery-rate-based charge is just another way to extract money from the publisher, and will erect barriers to publishers that cannot afford a higher quality of service. This discrimination will prevent publishers (and even individuals) from being able to publish merely based on financial means.
The aforementioned components and initiatives of the COPE Act-economic growth, universal access, anti-redlining, and "net neutrality" safeguarding-are key to allowing Internet access to grow and remain unimpeded.
The key to the growth of access to the Internet is NOT to allow the carriers one more loophole by which they can charge the publishers to provide the delivery of data that BOTH the publisher and consumer have ALREADY paid for in terms of the connection and data rates purchased.
Experience tells us that if you do NOT prevent this extortionary charge, the bandwidth providers will charge the publishers, and that this kind of charge (for services already provided) will be levied at every level, ultimately eliminating the free and open access to information that makes the Internet such a powerful source of information and innovation.
Please reconsider the importance of this CRITICAL amendment to an otherwise good legislation. Your failure to add SPECIFIC language to prevent this pay-by-rate charges will be considered a failure of you to represent me in an area near and dear to my heart. I would be hard-pressed to support you in further elections.
Sincerely, Marc C. Brooks
Go to this page... and wait... and wait... okay, now right-click and select View Source... and wait... and wait... okay, now check out the file size and line count. You should see (assuming you are using Notepad2 or some such editor) this: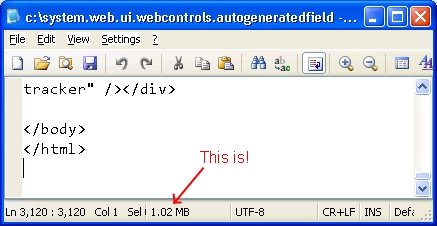
In what reality is rendering a 1.02 megabyte, 3120 line page reasonable? Certainly not over the web! No wonder all these MSDN2 pages take forever to render.
Jason Bock is right. For the first time in my blog reading history, I'm dropping a blog. The irony is that I'm dropping Jason's blog. I just don't want to read another rant about how there is no god, or how fundamentalists are stupid, or how wonderful it is to be able to explain everything through the wonders of science.
Don't get me wrong, I love the scientific method and the gains in understanding it enables. I'm just not cocky enough to believe than our (humankind's) cumulative knowlege is every going to be sufficient to fully explain the universe that contains us. What there is outside of what we can understand is open to debate and faith. That is, unless you want to deny it exists simply because you can't apply science to discover it completely.
Unsubscribed.
There is a nice new site to head to that aggregates many .Net relate blogs and also has a forum area for Atlas-related things. Garbin has already posted a couple controls there. Head over and see how it looks.
Continuing the recommended book list from part one, here's my short list of SQL books:
That's about it for this cut, I'll update when I think of others. Stay tuned for posts about language-specific and platform-specific books. Don't miss my first part with the basics.
I have been asked so many times, so I'm putting the list here. I'll updated it from time to time, but this is my list:
That's about it for this cut, I'll update when I think of others. Stay tuned for posts about SQL, language-specific and platform-specific books.
If you've ever wished you had cross-browser support for SVG-type graphics everywhere, check out the cool DIV-based work of Walter Zorn. DHTML: Draw Line, Ellipse, Oval, Circle, Polyline, Polygon, Triangle with JavaScript
 .Net
(35)C#
(20)Microsoft
(18)Dynamic
(16)LCG
(16)lightweight code generation
(15)DynamicMethod
(14)SQL
(14)CodePlex
(13)fun
(13)Asp.Net
(12)IL
(9)best practice
(8)bug
(8)DateTime
(7)personal
(7)Emit
(6)RSS
(6)blinding science
(6)MethodInfo
(5)Reflection
(5)CLR
(4)RssToolkit
(4)URI
(4)UriTemplate
(4)exception
(4)DataSource
(3)GetHashCode
(3)IFilter
(3)LocalDB
(3)ObjectDataSource
(3)REST
(3)SQL Server 2005
(3)UriPattern
(3)Web design
(3)books
(3)code review
(3)cool
(3)funny
(3)job
(3)meme
(3)rant
(3)Annoyances
(2)Backup
(2)COM
(2)DATEADD
(2)DATEDIFF
(2)DynamicComparer
(2)HTML
(2)IDL
(2)Internet Explorer
(2)MVC
(2)Politics
(2)Serialization
(2)Source
(2)TFS
(2)Team Foundation
(2)Utilities
(2)Visual Studio
(2)end of month
(2)interesting
(2)javascript
(2)kids
(2)music
(2)rants
(2)zebra fun
(2)ArgumentValidation
(1)Atom
(1)C++
(1)CDN
(1)CSS
(1)CompareTo
(1)Connect
(1)Crypto
(1)Cryptography
(1)DRM
(1)Database
(1)DisposableAction
(1)Double
(1)Enterprise Library
(1)EntityFramwork
(1)Enum
(1)Equals
(1)FCL
(1)GitHub
(1)HotFix
(1)IE
(1)IIS
(1)IP Address
(1)Insert
(1)Ladybug
(1)Localization
(1)Locks
(1)Nullable
(1)OperationContext
(1)RDF
(1)Random
(1)Recovery
(1)Restore
(1)SOAP
(1)SQL Server
(1)SQLServer
(1)SSDS
(1)SSO
(1)SVG
(1)Secunia
(1)Shelveset
(1)Sidekick
(1)Single sign-on
(1)UDT
(1)UndoableAction
(1)Vista
(1)WCF
(1)WF
(1)WTF
(1)WebForms
(1)Workflow
(1)XEN
(1)XML
(1)antivirus
(1)architecture
(1)authentication
(1)cURL SQL Server Data Services
(1)concurrency
(1)delegates
(1)generic
(1)goodbye
(1)injection
(1)patch
(1)patterns and practice
(1)performance
(1)provider
(1)query notifications
(1)references
(1)sad
(1)stupid studies
(1)thread
(1)thread-safe
(1)tools
(1)validation
(1)visualizer
(1)whatwg
(1)
.Net
(35)C#
(20)Microsoft
(18)Dynamic
(16)LCG
(16)lightweight code generation
(15)DynamicMethod
(14)SQL
(14)CodePlex
(13)fun
(13)Asp.Net
(12)IL
(9)best practice
(8)bug
(8)DateTime
(7)personal
(7)Emit
(6)RSS
(6)blinding science
(6)MethodInfo
(5)Reflection
(5)CLR
(4)RssToolkit
(4)URI
(4)UriTemplate
(4)exception
(4)DataSource
(3)GetHashCode
(3)IFilter
(3)LocalDB
(3)ObjectDataSource
(3)REST
(3)SQL Server 2005
(3)UriPattern
(3)Web design
(3)books
(3)code review
(3)cool
(3)funny
(3)job
(3)meme
(3)rant
(3)Annoyances
(2)Backup
(2)COM
(2)DATEADD
(2)DATEDIFF
(2)DynamicComparer
(2)HTML
(2)IDL
(2)Internet Explorer
(2)MVC
(2)Politics
(2)Serialization
(2)Source
(2)TFS
(2)Team Foundation
(2)Utilities
(2)Visual Studio
(2)end of month
(2)interesting
(2)javascript
(2)kids
(2)music
(2)rants
(2)zebra fun
(2)ArgumentValidation
(1)Atom
(1)C++
(1)CDN
(1)CSS
(1)CompareTo
(1)Connect
(1)Crypto
(1)Cryptography
(1)DRM
(1)Database
(1)DisposableAction
(1)Double
(1)Enterprise Library
(1)EntityFramwork
(1)Enum
(1)Equals
(1)FCL
(1)GitHub
(1)HotFix
(1)IE
(1)IIS
(1)IP Address
(1)Insert
(1)Ladybug
(1)Localization
(1)Locks
(1)Nullable
(1)OperationContext
(1)RDF
(1)Random
(1)Recovery
(1)Restore
(1)SOAP
(1)SQL Server
(1)SQLServer
(1)SSDS
(1)SSO
(1)SVG
(1)Secunia
(1)Shelveset
(1)Sidekick
(1)Single sign-on
(1)UDT
(1)UndoableAction
(1)Vista
(1)WCF
(1)WF
(1)WTF
(1)WebForms
(1)Workflow
(1)XEN
(1)XML
(1)antivirus
(1)architecture
(1)authentication
(1)cURL SQL Server Data Services
(1)concurrency
(1)delegates
(1)generic
(1)goodbye
(1)injection
(1)patch
(1)patterns and practice
(1)performance
(1)provider
(1)query notifications
(1)references
(1)sad
(1)stupid studies
(1)thread
(1)thread-safe
(1)tools
(1)validation
(1)visualizer
(1)whatwg
(1)



